 2024/11/24 09:56
2024/11/24 09:56
加州大学旧金山分校:一种双语言语神经假体(脑机接口)
2024/11/24 09:56
失语症,即失去言语表达能力,可能是中风和肌萎缩侧索硬化症等神经系统疾病的严重症状。为恢复失语和瘫痪患者自然交流能力,正在开发解码皮层活动为预期言语的侵入性语言脑-机接口(BCIs)。特别是皮层内电极、立体脑电图和皮层脑电图(ECoG),其中ECoG直接从皮层表面记录电信号,可以捕捉与言语产生相关的神经活动。然而,由于研究群体的抽样限制,言语BCI的进展主要集中在解码单一语言,主要是英语或荷兰语。单语言和英语解码的重点不仅限于言语神经假体;在自动语音识别和语言建模中也存在类似趋势。因此,双语者及非英语使用者的语言技术往往发展较少。
世界人口中大约三分之二是双语者,即能够熟练使用两种或更多语言的个体。研究表明,一个人所掌握的多种语言在交流中具有互补功能。例如,双语者通常报告他们在不同的说话者和社交情境中使用不同的语言(L1-母语和L2-后天习得的语言;在某些情况下,L2也可能是母语),并进一步表示他们所讲的语言为其整体人格和世界观带来了不同的维度。为了开发一种能够为所有受益者恢复具身交流功能的神经假体,无论其语言背景如何,有必要设计能够进行多语言解码的BCI系统。
加州大学旧金山分校(University of California, San Francisco)的科学家们开发了一种双语大脑植入物,该植入物利用人工智能首次帮助中风患者用西班牙语和英语进行交流。来自该大学神经工程和假肢中心的近十来位科学家经过数年的努力,设计出了一种解码系统,可以将该男子的大脑活动转化为两种语言的句子,并在屏幕上显示出来。

5月20日发表在《Nature Biomedical Engineering》杂志上的一篇文章,概述了他们的研究工作。这项研究的参与者,绰号"Pancho(潘乔)",20岁时因中风导致身体大部分瘫痪。因此,他只能发出呻吟和咕哝声,却不能清楚地说话。他的母语是西班牙语,成年后开始学习英语。
30多岁时,潘乔与加州大学旧金山分校(University of California, San Francisco)的神经外科医生爱德华·张(Edward Chang)合作,研究中风对他大脑的持久影响。在2012年发表的一项开创性研究中,Chang的团队通过手术将电极植入Pancho的皮层,以记录神经活动,并将其转化为屏幕上的文字。
1.双语言语神经假体的性能
本文设计了一个系统,能够灵活地解码因脑干中风而瘫痪和无关节的参与者的英语和西班牙语短语。我们的模型在高密度、128通道ECoG阵列的神经特征上进行了训练,该阵列主要覆盖左侧感觉运动皮层和额下回。

如图1。a. 双语解码系统的示意图。在每次试验中,参与者会收到一个英语或西班牙语的目标短语。参与者通过尝试发声主动激活系统,语音检测模型从神经特征中识别出该尝试。检测到初始尝试发声事件后,系统每3.5秒提示参与者尝试说出句子的下一个单词。每个时间窗口中的神经特征通过一个由递归神经网络(RNN)层和一个全连接密集层组成的分类器进行处理,生成104个可能单词(51个英语单词,50个西班牙语单词和3个共享单词)的概率分布。英语和西班牙语单词的概率向量分别处理。这里,未变位的动词或形容词的神经概率会扩展到所有变位形式,总共有178个独特单词(67个英语单词,108个西班牙语单词和3个共享单词)由n-gram语言模型评分。在每个窗口结束时选择最可能的短语并显示给参与者。当在3.5秒的时间窗口内未检测到发声尝试时,系统将被停用。
2.神经解码性能的离线表征
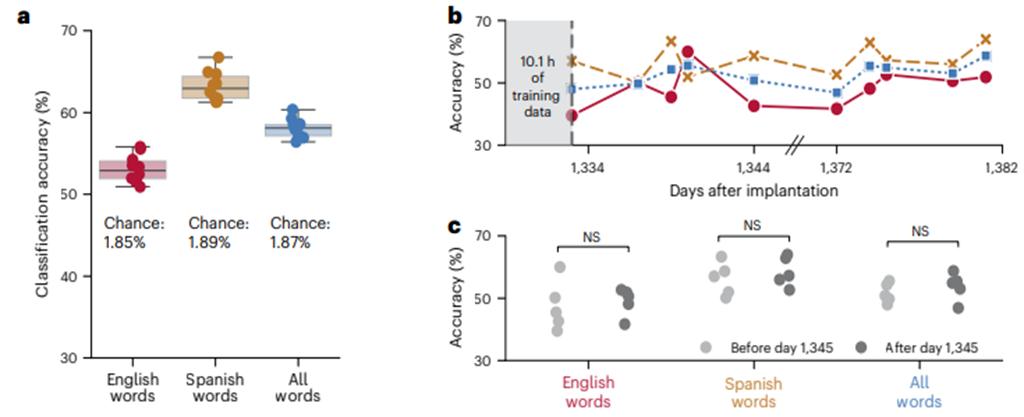
为了进一步表征我们的系统从神经特征中解码英语和西班牙语单词的能力,我们使用 10 倍交叉验证 (CV) 来评估收集的孤立目标数据的分类性能,以训练短语解码模型。如下图2(a). 英语单词、西班牙语单词及跨语言(所有单词)的10倍交叉验证分类准确率。分布在10个不重叠的折叠中。b. 在不重新训练或重新校准系统的情况下,48天内对英语单词、西班牙语单词及跨语言单词进行分类。分类器从训练期收集的数据中训练,然后权重被冻结(黑色虚线)。结果是在ECoG设备植入3.5年后获得的。坐标轴中的中断表示记录过程中有30天的间隔。在这30天的间隔中,没有进行重新训练。
3.言语运动皮层中英语和西班牙短语的共享皮层表征
本文以与模型无关的方式直接探测了参与者电极阵列中英语和西班牙语语音的神经表征。本文设计了多个独特的短语,每种语言有大约200个单词(图3a),以对每种语言的更大发音空间进行采样。这使我们能够在更大的词汇空间内评估不同语言之间神经活动的幅度或定位是否不同。
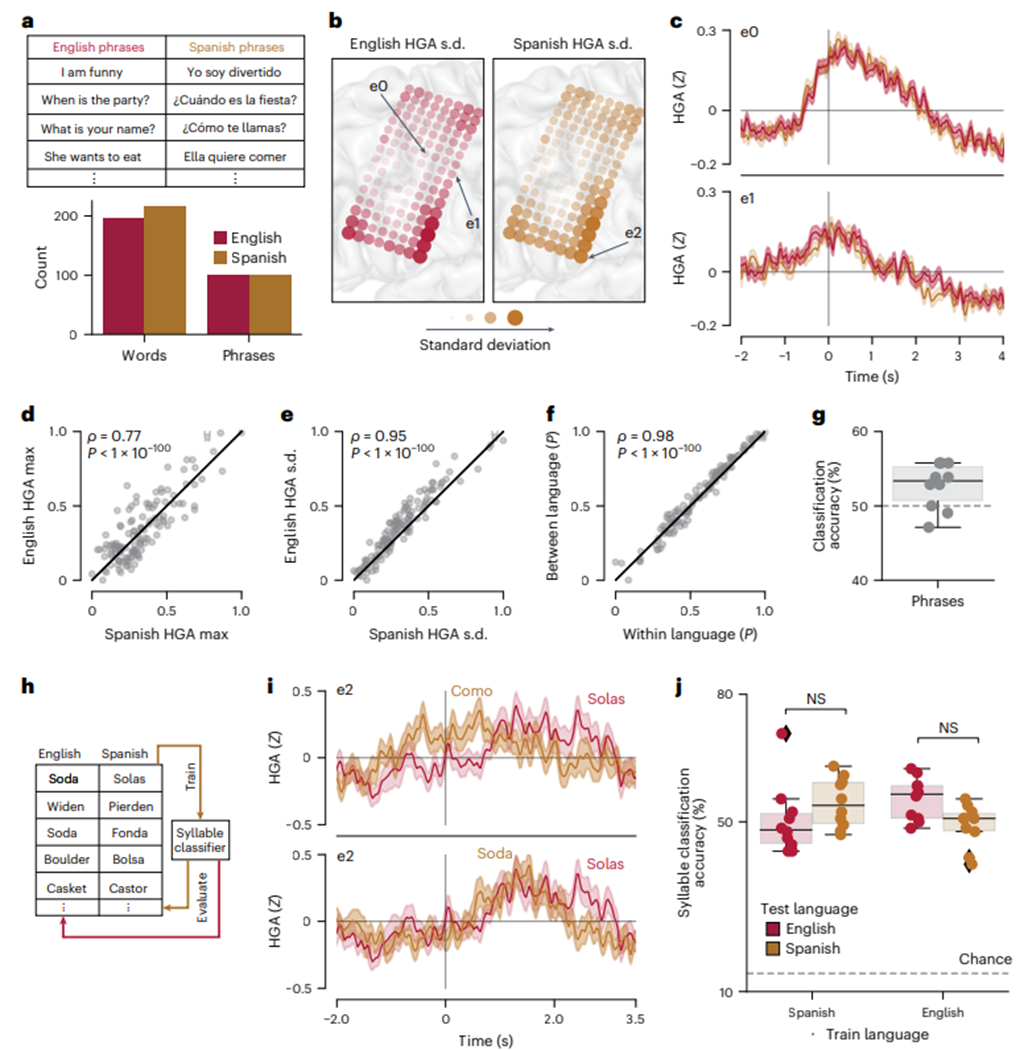
如图3. a. 使用大型刺激集,包括独特的单词和短语,以覆盖每种语言中更全面的发音空间,相对于用于短语解码的词汇(图1)。b. 各电极在英语和西班牙语短语中从0到2秒(相对于视觉“开始”提示)的平均HGA标准偏差。c. 两个电极在英语和西班牙语短语中的示例ERP,如b所示。d. 英语和西班牙语短语中每个电极的最大HGA之间的关系。e. 每个电极在英语和西班牙语短语中的HGA标准偏差(如b所示)之间的关系。f. 每个电极在单一语言内的ERP相关性与跨语言的ERP相关性之间的关系。
4.共享音节表示跨语言分类器的训练和测试的可能性
与参与者一起,我们评估了一个音节分类器是否可以在英语和西班牙语之间泛化。我们设计了一个话语集,在这个话语集中,相同的7个音节出现在7个英语和西班牙语单词中。来自一个样本电极的ERP显示了相同音节在不同语言中的神经活动存在明显的相似性(图3i)。接下来,我们使用参与者尝试说英语或西班牙语单词时记录的神经数据,对共享音节集训练了音节分类模型。我们在相同语言的保留数据或另一种语言的数据上评估了这些模型。我们的音节分类器在训练和测试发生在相同语言时均取得了很高的性能(图3j;P=0.08和P=0.03,双侧Mannhitney U检验,分别为训练英语(西班牙语)和测试西班牙语(英语))。这提供了令人信服的证据,即共享音节表示可以使在一种语言中收集的数据被重新用于第二种语言。
5.语言之间的快速迁移学习
迁移学习是机器学习中的一种常用技术,涉及使用在单独的任务或数据集上学习的参数初始化模型权重。迁移学习主要用于神经解码,以利用在先前参与者中训练的模型来加快新参与者的训练。
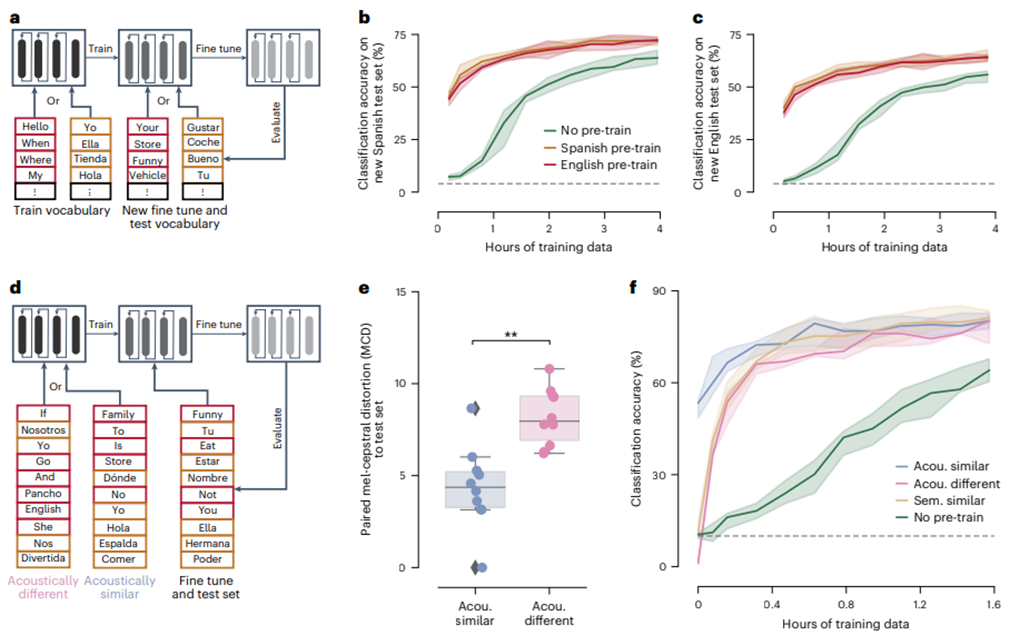
如图4. a. 评估语言间迁移学习的范式示意图。模型在英语或西班牙语词汇上进行训练,然后在新的英语或西班牙语词汇上进行微调和评估。b. 微调和评估新西班牙语词汇时,训练数据量(学习曲线)与中位分类准确率的关系。c. 微调和评估新英语词汇时,训练数据量(学习曲线)与中位分类准确率的关系。在b-c中,模型要么未经过预训练,要么在不同的英语或西班牙语词汇上进行了预训练。解码概率水平为4%。d. 用于评估训练集和微调集之间声学相似性对迁移学习效果影响的范式示意图。

讨论
我们利用言语运动皮层中的共享发音表征来驱动双语言语神经假体。我们实现了低单词错误率,可用于临床环境,当目标语言根据神经特征自由解码时,具有很高的语言分类准确性,重要的是,在整个短语中构建的差异语言上下文。植入后1300多天,我们基于ECoG的神经分类算法表现出稳定的性能,无需重新训练超过40天。我们还观察到,在对仅以另一种语言收集的数据进行训练后,对给定语言中的音节进行了稳健的解码。相应地,语言之间的迁移学习促进了第二语言新词汇的学习,而新训练数据则只有1小时。总之,这组发现与自动语音识别的进步并行不悖,将通信技术带给多语言和非英语使用者。
值得注意的是,参与者以西班牙语为母语(L1),然后在成年后学习英语(L2),在任何关键的习得期之后。然而,在我们的覆盖范围中没有发现任何皮层区域或神经活动模式,特定于英语或西班牙语的语音尝试。尽管后来获得了L2(大约在参与者的脑干中风时间),我们也没有注意到 L1 和 L2 之间诱发活动的显着差异
文献地址
Silva A B, Liu J R, Metzger S L, et al. A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages[J]. Nature Biomedical Engineering, 2024: 1-15.
https://doi.org/10.1038/s41551-024-01207-5
仅用于学术分享,若侵权请留言,即时删侵!
本文来自新知号自媒体,不代表商业新知观点和立场。
若有侵权嫌疑,请联系商业新知平台管理员。
联系方式:system@shangyexinzhi.com